PROGRAMACIÓN

TEMARIO
1.- LÓGICA DE PROGRAMACIÓN.
1.1.-ALGORITMO
1.2.- DIAGRAMA DE FLUJO.
1.3.-PSEUDOCODIGO.
1.4.-DECISIONES.
1.5.-CICLO.
2.-LENGUAJE DEl PROGRAMA.
2.1.-TIPO DE LENGUAJE.
2.2.-METODOLÓGICA DE LA PROGRAMACIÓN.
2.2.1.-ESTRUCTURA.
2.2.2.-ORIENTADO A OBJETO.
3.-PROGRAMACIÓN UTILIZANDO UN LENGUAJE DE ALTO NIVEL.
3.1.-ENTORNO DE DESARROLLO.
3.2.-VARIABLES.
3.3.-OPERADORES.
3.4.-CONSTANTES.
3.5.-PALABRAS RESERVADAS.
3.6.-SENTENCIA DE DECISIÓN.
3.7.- ESTRUCTURA.
3.7.1.-CONDICIÓN.
3.7.2.-REPETICIÓN.
4.-ARREGLOS.
1.- LÓGICA DE PROGRAMACIÓN.
Lógica de programación: el primer paso para aprender a programar

Usualmente encontramos personas interesadas en tecnología y programación queno saben exactamente por dónde comenzar a estudiar. Pensando en esto, preparamos un post especial para ayudarte en el primer paso para acercarte al tema. ¡Ven y entérate de la importancia de la lógica de programación y los algoritmos!
Hay algunas cuestiones esenciales para iniciar los estudios en programación. Entre ellas se destaca la dedicación en practicar y aprender de los errores; además de la afinidad con matemática e inglés.
El estudio de la programación está conectada al área de ciencias exactas, y la matemática con sus reglas estará presente en diversos momentos. Por otro lado el inglés -hoy fundamental en cualquier profesión- también será importante, ya que para programar encontrarás una variedad mayor de cursos y materiales en este idioma. Y además, la mayoría de los lenguajes de programación utilizan el inglés como base.
Inicialmente lo que genera más preocupación es la famosa pregunta: ¿Qué lenguaje debo comenzar a aprender? Pero el lenguaje en sí no importa mucho al inicio, porque la lógica es la misma para todos, por eso comenzar aprendiendo la lógica de programación es la mejor forma.
Ella es la base de todo el conocimiento en programación, ya que con la lógica aprendes a escribir un código para que la computadora interprete correctamente. Es decir que aprendes a comunicarte con la máquina a partir de un lenguaje.
Lógica de programación
¿Qué es exactamente la lógica de programación?
Lógica es la técnica utilizada para desarrollar instrucciones en una secuencia para lograr determinado objetivo.
Es la organización y planificación de instrucciones en un algoritmo, con el objetivo de tornar viable la implementación de un programa o software.
La lógica de la programación es la organización coherente de las instrucciones del programa para que su objetivo sea alcanzado.
Ese es el gran desafío del programador: montar una estructura del programa para ser ejecutado por la computadora. Y es necesario partir del principio que la computadora no piensa de la misma forma que el ser humano, y no es inteligente para saber qué es lo que tiene que hacer, ni comprender mensajes subjetivos.
Por eso organizar la información de forma clara y en el orden adecuado es primordial para la acción sea ejecutada correctamente.
1.1.-ALGORITMO
CONCEPTO Y CARACTERÍSTICAS DE ALGORITMOS
El objetivo fundamental de este texto es enseñar a resolver problemas mediante una computadora. El programadorde computadora es antes que nada una persona que resuelve problemas, por lo que para llegar a ser un programador eficaz se necesita aprender a resolver problemas de un modo riguroso y sistemático. A lo largo de todo este libro nosreferiremos a la metodología necesaria para resolver problemas mediante programas, concepto que se denomina metodología de la programación. El eje central de esta metodología es el concepto, ya tratado, de algoritmo. Un algoritmo es un método para resolver un problema. Aunque la popularización del término ha llegado con el advenimiento de la era informática, algoritmo proviene —como se comentó anteriormente— de Mohammed al- KhoWârizmi, matemático persa que vivió durante el siglo IX y alcanzó gran reputación por el enunciado de las reglas paso a paso para sumar, restar, multiplicar y dividir números decimales; la traducción al latín del apellido en la palabra algorismus derivó posteriormente en algoritmo. Euclides, el gran mate mático griego (del siglo IV a. C.) queinventó un método para encontrar el máximo común divisor de dos números, se considera con Al-Khowârizmi el otrogran padre de la algoritmia (ciencia que trata de los algoritmos).
El profesor Niklaus Wirth —inventor de Pascal, Modula-2 y Oberon— tituló uno de sus más famosos libros, Algoritmos + Estructuras de datos = Programas, significándonos que sólo se puede llegar a realizar un buen programa con el diseño de un algoritmo y una correcta estructura de datos. Esta ecuación será una de las hipótesis fundamentales consideradas en esta obra.
La resolución de un problema exige el diseño de un algoritmo que resuelva el problema propuesto.

Los
pasos para la resolución de un problema son:
1. Diseño del algoritmo, que
describe la secuencia ordenada de pasos —sin ambigüedades— que conducen a la solución
de un problema dado. (Análisis del problema y desarrollo del
algoritmo.)
2.
Expresar el algoritmo como un programa en
un lenguaje de programación adecuado. (Fase de
codificación.)
3. Ejecución y validación del programa por la computadora.
Para
llegar a la realización de un programa es necesario el diseño previo de un
algoritmo, de modo que sin algoritmo no puede existir un programa.
Los
algoritmos son independientes tanto del lenguaje de programación en que se expresan
como de la computadora que los ejecuta. En cada problema el algoritmo se puede
expresar en un lenguaje diferente de programación y ejecutarse en una
computadora distinta; sin embargo, el algoritmo será siempre el mismo. Así, por
ejemplo, en una analogía con la vida diaria, una receta de un plato de cocina
se puede expresar en español, inglés o francés, pero cualquiera que sea el
lenguaje, los pasos para la elaboración del plato se realizarán sin importar el
idioma del cocinero.
En
la ciencia de la computación y en la programación, los algoritmos son más importantes
que los lenguajes de programación o las computadoras. Un lenguaje de
programación es tan sólo un medio para expresar un algoritmo y una computadora
es sólo un procesador para ejecutarlo. Tanto el lenguaje de programación como
la computadora son los medios para obtener un fin: conseguir que el algoritmo
se ejecute y se efectúe el proceso correspondiente. Dada la importancia del
algoritmo en la ciencia de la computación, un aspecto muy importante será el diseño de algoritmos. A la
enseñanza y práctica de esta tarea se dedica gran parte de este libro.
El
diseño de la mayoría de los algoritmos requiere creatividad y conocimientos
profundos de la técnica de la programación. En esencia, la solución de un problema se puede expresar mediante un
algoritmo.
Características de los algoritmos
Las
características fundamentales que debe cumplir todo algoritmo son:
• Un
algoritmo debe ser preciso e
indicar el orden de realización de cada paso.
• Un
algoritmo debe estar bien definido.
Si se sigue un algoritmo dos veces, se debe obtener el mismo resultado cada vez.
• Un
algoritmo debe ser finito.
Si se sigue un algoritmo, se debe terminar en algún momento; o sea, debe tener un
número finito de pasos.
La
definición de un algoritmo debe describir tres partes: Entrada, Proceso y Salida. En el algoritmo de
receta de cocina citado anteriormente se tendrá:
Entrada: Ingredientes y
utensilios empleados.
Proceso: Elaboración de la
receta en la cocina.
Salida: Terminación del plato
(por ejemplo, cordero).
Se desea diseñar un algoritmo para saber si un número es
primo o no.
Un
número es primo si sólo puede dividirse por sí mismo y por la unidad (es decir,
no tiene más divisores que él mismo y la unidad). Por ejemplo, 9, 8, 6, 4, 12,
16, 20, etc., no son primos, ya que son divisibles por números distintos a
ellos mismos y a la unidad. Así, 9 es divisible por 3, 8 lo eslo es por 2, etc.
El algoritmo de resolución delproblema pasa por dividir sucesivamente el número
por 2, 3, 4..., etc.

1.2.- DIAGRAMA DE FLUJO.
Un diagrama de flujo (flowchart) es una de las técnicas de representación de algoritmos más antigua y a la vez más utilizada, aunque su empleo ha disminuido considerablemente, sobro todo, desde la aparición de lenguajes de programación estructurados. Un diagrama de flujo es un diagrama que utiliza los símbolos (cajas) estándar mostrados en la Tabla 2.1 y que tiene los pasos de algoritmo escritos en esas cajas unidas por flechas, denominadas líneas de flujo, que indican la secuencia en que se debe ejecutar.
Es un diagrama de flujo básico. Este diagrama representa la resolución de un programa que deduce el salario neto de un trabajador a partir de la lectura del nombre, horas trabajadas, precio de la hora, y sabiendo que los impuestos aplicados son el 25 por 100 sobre el salario bruto.
Los símbolos estándar normalizados por ANSI (abreviatura de American National Standars Institute) son muy variados. En la Figura 2.18 se representa una plantilla de dibujo típica donde se contemplan la mayoría de los símbolos utilizados en el diagrama; sin embargo, los símbolos más utilizados representan:
proceso • decisión • conectores
• fin • entrada/salida • dirección del flujo
El diagrama de flujo sus características:
• existe una caja etiquetada “inicio”, que es de tipo elíptico,
• existe una caja etiquetada “fin” de igual forma que la anterior,
• si existen otras cajas, normalmente son rectangulares, tipo rombo o paralelogramo (el resto de las figuras se utilizan sólo en diagramas de flujo generales o de detalle y no siempre son imprescindibles).

1.3.-PSEUDOCODIGO.
El
pseudocódigo es un lenguaje de especificación
(descripción) de algoritmos. El uso de
tal lenguaje hace el paso de codificación final (esto es, la traducción a un
lenguaje de programación) relativamente fácil. Los lenguajes APL Pascal y Ada
se utilizan a veces como lenguajes de especificación de algoritmos. El
pseudocódigo nació como un lenguaje similar al inglés y era un medio de
representar básicamente las estructuras de control de programación estructurada
que se verán en capítulos posteriores. Se considera un primer borrador, dado que
el pseudocódigo tiene que traducirse posteriormente a un lenguaje de programación.
El pseudocódigo no puede ser ejecutado por una computadora. La ventaja del pseudocódigo es
que en su uso, en la planificación de un programa, el programador se puede
concentrar en la lógica y en las estructuras de control y no preocuparse de las
reglas de un lenguaje específico. Es también fácil modificar el pseudocódigo si
se descubren errores o anomalías en la lógica del programa, mientras que en
muchas ocasiones suele ser difícil el cambio en la lógica, una vez que está codificado
en un lenguaje de programación. Otra ventaja del pseudocódigo es que puede ser
traducido fácilmente a lenguajes estructurados como Pascal, C, FORTRAN 77/90,
C++, Java, C#, etc.
start
El
algoritmo comienza con la palabra start y finaliza con la
palabra end,
en inglés (en español, inicio,
fin).
Entre estas palabras, sólo se escribe una instrucción o acción por línea. La
línea precedida por // se denomina
comentario. Es
una información al lector del programa y no realiza ninguna instrucción
ejecutable, sólo tiene efecto de documentación interna del programa. Algunos
autores suelen utilizar corchetes o llaves.
Otro
ejemplo aclaratorio en el uso del pseudocódigo podría ser un sencillo algoritmo
del arranque matinal de un coche.
inicio
Por
fortuna, aunque el pseudocódigo nació como un sustituto del lenguaje de
programación y, por consiguiente, sus palabras reservadas se conservaron o
fueron muy similares a las del idioma inglés, el uso del pseudocódigo se ha extendido
en la comunidad hispana con términos en español como inicio, fin, parada, leer, escribir,
si-entonces-
1.4.-DECISIONES.
Decisiones: Son estructuras de control que realizan una pregunta la cual retorna verdadero o falso (evalúa una condición) y selecciona la siguiente instrucción a ejecutar dependiendo la respuesta o resultado. El siguiente enlace nos dará una mejor visión con respecto a las decisiones:
 Las sentencias de decisión o también llamadas de CONTROL DE FLUJO son estructuras de control que realizan una pregunta la cual retorna verdadero o falso (evalúa una condicion) y selecciona la siguiente instrucción a ejecutar dependiendo la respuesta o resultado.
Las sentencias de decisión o también llamadas de CONTROL DE FLUJO son estructuras de control que realizan una pregunta la cual retorna verdadero o falso (evalúa una condicion) y selecciona la siguiente instrucción a ejecutar dependiendo la respuesta o resultado.
En algún momento dentro de nuestros algoritmos, es preciso cambiar el flujo de ejecución de las instrucciones, es decir, el orden en que las instrucciones son ejecutadas. Muchas de las veces tenemos que tomar una decisión en cuanto a que se debe ejecutar basándonos en una respuesta de verdadero o falso (condicion).
La ejecución de las instrucciones incluyendo una estructura de control como el condicional funcionan de esta manera:
Las instrucciones comienzan a ejecutarse de forma secuencial (en orden) y cuando se llega a una estructura condicional, la cual esta asociada a una condicion, se decide que camino tomar dependiendo siempre del resultado de la condicion siendo esta falsa o verdadera.
Cuando se termina de ejecutar este bloque de instrucciones se reanuda la ejecución en la instrucción siguiente a la de la condicional.
1.5.-CICLO.
Ciclos o bucles (repetir hasta, repetir mientras y repetir desde): Es una sentencia que se realiza repetidas veces a un trozo aislado de código, hasta que la condición asignada a dicho bucle deje de cumplirse.
Generalmente, un bucle es utilizado para hacer una acción repetida sin tener que escribir varias veces el mismo código, lo que ahorra tiempo, deja el código más claro y facilita su modificación en el futuro.
El bucle y los condicionales representan la base de la programación estructurada. Es una evolución del código ensamblador, donde la única posibilidad de iterar un código era establecer una sentencia jump (que en los lenguajes de programación fue sustituida por el "ir a" o GOTO).
Los tres bucles más utilizados en programación son el bucle while, el bucle for y el bucle repetir. El siguiente enlace nos dará una mejor visión con respecto a los ciclos:
Bucle mientras
El bucle se repite mientras la condición sea cierta, si al llegar por primera vez al bucle mientras la condición es falsa, el cuerpo del bucle no se ejecuta ninguna vez.
Bucle repetir
Existen otras variantes que se derivan a partir de la anterior. La estructura de control repetir se utiliza cuando es necesario que el cuerpo del bucle se ejecuten al menos una vez y hasta que se cumpla la condición:
Bucle para
Una estructura de control muy común es el ciclo para, la cual se usa cuando se desea iterar un número conocido de veces, empleando como índice una variable que se incrementa (o decrementa).
Es importante recalcar que el pseudocódigo no es un lenguaje estandarizado. Eso significa que diferentes autores podrían dar otras estructuras de control o bien usar estas mismas estructuras, pero con una notación diferente. Sin embargo, las funciones matemáticas y lógicas toman el significado usual que tienen en matemática y lógica, con las mismas expresiones.
2.-LENGUAJE DE PROGRAMA
1.2.- DIAGRAMA DE FLUJO.
Un diagrama de flujo (flowchart) es una de las técnicas de representación de algoritmos más antigua y a la vez más utilizada, aunque su empleo ha disminuido considerablemente, sobro todo, desde la aparición de lenguajes de programación estructurados. Un diagrama de flujo es un diagrama que utiliza los símbolos (cajas) estándar mostrados en la Tabla 2.1 y que tiene los pasos de algoritmo escritos en esas cajas unidas por flechas, denominadas líneas de flujo, que indican la secuencia en que se debe ejecutar.
Es un diagrama de flujo básico. Este diagrama representa la resolución de un programa que deduce el salario neto de un trabajador a partir de la lectura del nombre, horas trabajadas, precio de la hora, y sabiendo que los impuestos aplicados son el 25 por 100 sobre el salario bruto.
Los símbolos estándar normalizados por ANSI (abreviatura de American National Standars Institute) son muy variados. En la Figura 2.18 se representa una plantilla de dibujo típica donde se contemplan la mayoría de los símbolos utilizados en el diagrama; sin embargo, los símbolos más utilizados representan:
proceso • decisión • conectores
• fin • entrada/salida • dirección del flujo
El diagrama de flujo sus características:
• existe una caja etiquetada “inicio”, que es de tipo elíptico,
• existe una caja etiquetada “fin” de igual forma que la anterior,
• si existen otras cajas, normalmente son rectangulares, tipo rombo o paralelogramo (el resto de las figuras se utilizan sólo en diagramas de flujo generales o de detalle y no siempre son imprescindibles).

1.3.-PSEUDOCODIGO.
El
pseudocódigo es un lenguaje de especificación
(descripción) de algoritmos. El uso de
tal lenguaje hace el paso de codificación final (esto es, la traducción a un
lenguaje de programación) relativamente fácil. Los lenguajes APL Pascal y Ada
se utilizan a veces como lenguajes de especificación de algoritmos. El
pseudocódigo nació como un lenguaje similar al inglés y era un medio de
representar básicamente las estructuras de control de programación estructurada
que se verán en capítulos posteriores. Se considera un primer borrador, dado que
el pseudocódigo tiene que traducirse posteriormente a un lenguaje de programación.
El pseudocódigo no puede ser ejecutado por una computadora. La ventaja del pseudocódigo es
que en su uso, en la planificación de un programa, el programador se puede
concentrar en la lógica y en las estructuras de control y no preocuparse de las
reglas de un lenguaje específico. Es también fácil modificar el pseudocódigo si
se descubren errores o anomalías en la lógica del programa, mientras que en
muchas ocasiones suele ser difícil el cambio en la lógica, una vez que está codificado
en un lenguaje de programación. Otra ventaja del pseudocódigo es que puede ser
traducido fácilmente a lenguajes estructurados como Pascal, C, FORTRAN 77/90,
C++, Java, C#, etc.
El
pseudocódigo original utiliza para representar las acciones sucesivas palabras
reservadas en inglés —similares a sus homónimas en los lenguajes de
programación—, tales como start, end, stop, if-then-else,
while-end,
repeat-until,
etc. La escritura La escritura de pseudocódigo exige
normalmente la indentación (sangría
en el margen izquierdo) de diferentes líneas. Una representación en
pseudocódigo —en inglés— de un problema de cálculo del salario neto de un
trabajador es la siguiente:
start
//cálculo de impuesto y salarios
read
nombre,
horas, precio
salario ← horas * precio
tasas ← 0,25 * salario
salario_neto ← salario – tasas
write
nombre,
salario, tasas, salario
end
El
algoritmo comienza con la palabra start y finaliza con la
palabra end,
en inglés (en español, inicio,
fin).
Entre estas palabras, sólo se escribe una instrucción o acción por línea. La
línea precedida por // se denomina
comentario. Es
una información al lector del programa y no realiza ninguna instrucción
ejecutable, sólo tiene efecto de documentación interna del programa. Algunos
autores suelen utilizar corchetes o llaves.
No
es recomendable el uso de apóstrofos o simples comillas como representan en
algunos lenguajes primitivos los comentarios, ya que este carácter es
representativo de apertura o cierre de cadenas de caracteres en lenguajes como
Pascal o FORTRAN, y daría lugar a confusión.
Otro
ejemplo aclaratorio en el uso del pseudocódigo podría ser un sencillo algoritmo
del arranque matinal de un coche.
inicio
//arranque
matinal de un coche
introducir
la llave de contacto
girar
la llave de contacto
pisar
el acelerador
oir el
ruido del motor
pisar
de nuevo el acelerador
esperar
unos instantes a que se caliente el motor
fin
Por
fortuna, aunque el pseudocódigo nació como un sustituto del lenguaje de
programación y, por consiguiente, sus palabras reservadas se conservaron o
fueron muy similares a las del idioma inglés, el uso del pseudocódigo se ha extendido
en la comunidad hispana con términos en español como inicio, fin, parada, leer, escribir,
si-entonces-
si_no, mientras,
fin_mientras,
repetir,
hasta_que,
etc. Sin duda, el uso de la terminología del pseudocódigo en español ha
facilitado y facilitará considerablemente el aprendizaje y uso diario de la
programación. En esta obra, al igual que en otras nuestras, utilizaremos el
pseudocódigo en español y daremos en su momento las estructuras equivalentes en
inglés, al objeto de facilitar la traducción del pseudocódigo al lenguaje de
programación seleccionado.
1.4.-DECISIONES.
Decisiones: Son estructuras de control que realizan una pregunta la cual retorna verdadero o falso (evalúa una condición) y selecciona la siguiente instrucción a ejecutar dependiendo la respuesta o resultado. El siguiente enlace nos dará una mejor visión con respecto a las decisiones:
Las sentencias de decisión o también llamadas de CONTROL DE FLUJO son estructuras de control que realizan una pregunta la cual retorna verdadero o falso (evalúa una condicion) y selecciona la siguiente instrucción a ejecutar dependiendo la respuesta o resultado.
En algún momento dentro de nuestros algoritmos, es preciso cambiar el flujo de ejecución de las instrucciones, es decir, el orden en que las instrucciones son ejecutadas. Muchas de las veces tenemos que tomar una decisión en cuanto a que se debe ejecutar basándonos en una respuesta de verdadero o falso (condicion).
La ejecución de las instrucciones incluyendo una estructura de control como el condicional funcionan de esta manera:
Las instrucciones comienzan a ejecutarse de forma secuencial (en orden) y cuando se llega a una estructura condicional, la cual esta asociada a una condicion, se decide que camino tomar dependiendo siempre del resultado de la condicion siendo esta falsa o verdadera.
Cuando se termina de ejecutar este bloque de instrucciones se reanuda la ejecución en la instrucción siguiente a la de la condicional.
1.5.-CICLO.
Ciclos o bucles (repetir hasta, repetir mientras y repetir desde): Es una sentencia que se realiza repetidas veces a un trozo aislado de código, hasta que la condición asignada a dicho bucle deje de cumplirse.
Generalmente, un bucle es utilizado para hacer una acción repetida sin tener que escribir varias veces el mismo código, lo que ahorra tiempo, deja el código más claro y facilita su modificación en el futuro.
El bucle y los condicionales representan la base de la programación estructurada. Es una evolución del código ensamblador, donde la única posibilidad de iterar un código era establecer una sentencia jump (que en los lenguajes de programación fue sustituida por el "ir a" o GOTO).
Los tres bucles más utilizados en programación son el bucle while, el bucle for y el bucle repetir. El siguiente enlace nos dará una mejor visión con respecto a los ciclos:
Bucle mientras
El bucle se repite mientras la condición sea cierta, si al llegar por primera vez al bucle mientras la condición es falsa, el cuerpo del bucle no se ejecuta ninguna vez.
Bucle repetir
Existen otras variantes que se derivan a partir de la anterior. La estructura de control repetir se utiliza cuando es necesario que el cuerpo del bucle se ejecuten al menos una vez y hasta que se cumpla la condición:
Bucle para
Una estructura de control muy común es el ciclo para, la cual se usa cuando se desea iterar un número conocido de veces, empleando como índice una variable que se incrementa (o decrementa).
Es importante recalcar que el pseudocódigo no es un lenguaje estandarizado. Eso significa que diferentes autores podrían dar otras estructuras de control o bien usar estas mismas estructuras, pero con una notación diferente. Sin embargo, las funciones matemáticas y lógicas toman el significado usual que tienen en matemática y lógica, con las mismas expresiones.
2.-LENGUAJE DE PROGRAMA
Como se ha visto en el apartado anterior, para que un procesador realice un proceso se le debe suministrar en primer lugar un algoritmo adecuado. El procesador debe ser capaz de interpretar el algoritmo, lo que significa:
• comprender las instrucciones de cada paso,
• realizar las operaciones correspondientes.
Cuando el procesador es una computadora, el algoritmo se ha de expresar en un formato que se denomina programa, ya que el pseudocódigo o el diagrama de flujo no son comprensibles por la computadora, aunque pueda entenderlos cualquier programador. Un programa se escribe en un lenguaje de programación y las operaciones que conducen a expresar un algoritmo en forma de programa se llaman programación. Así pues, los lenguajes utilizados para escribir programas de computadoras son los lenguajes de programación y programadores son los escritores y diseñadores de programas. El proceso de traducir un algoritmo en pseudocódigo a un lenguaje de programación se denomina codificación, y el algoritmo escrito en un lenguaje de programación se denomina código fuente.
En la realidad la computadora no entiende directamente los lenguajes de programación, sino que se requiere un programa que traduzca el código fuente a otro lenguaje que sí entiende la máquina directamente, pero muy complejo para las personas; este lenguaje se conoce como lenguaje máquina y el código correspondiente código máquina.
Los programas que traducen el código fuente escrito en un lenguaje de programación —tal como C++— a código
máquina se denominan traductores.
El proceso de conversión de un algoritmo escrito en pseudocódigo hasta un
programa ejecutable comprensible por la máquina, se muestra en la Figura 1.14.

2.1.-TIPO DE LENGUAJE.
Hoy en día, la mayoría de los programadores emplean lenguajes de programación como C++, C, C#, Java, Visual Basic, XML, HTML, Perl, PHP, JavaScript..., aunque todavía se utilizan, sobre todo profesionalmente, los clásicos COBOL, FORTRAN, Pascal o el mítico BASIC. Estos lenguajes se denominan lenguajes de alto nivel y permiten a los profesionales resolver problemas convirtiendo sus algoritmos en programas escritos en alguno de estos lenguajes de programación.
Los lenguajes de programación se utilizan para escribir programas. Los programas de las computadoras modernas constan de secuencias de instrucciones que se codifican como secuencias de dígitos numéricos que podrán entender dichas computadoras. El sistema de codificación se conoce como lenguaje máquina que es el lenguaje nativo de una computadora. Desgraciadamente la escritura de programas en lenguaje máquina es una tarea tediosa y difícil ya que sus instrucciones son secuencias de 0 y 1 (patrones de bit, tales como 11110000, 01110011...) que son muy difíciles de recordar y manipular por las personas. En consecuencia, se necesitan lenguajes de programación amigables con el programador” que permitan escribir los programas para poder “charlar” con facilidad con las computadoras. Sin embargo, las computadoras sólo entienden las instrucciones en lenguaje máquina, por Lo que será preciso traducir los programas resultantes a lenguajes de máquina antes de que puedan ser ejecutadas por ellas.Cada lenguaje de programación tiene un conjunto o “juego” de instrucciones (acciones u operaciones que debe realizar la máquina) que la computadora podrá entender directamente en su código máquina o bien se traducirán a dicho código máquina. Las instrucciones básicas y comunes en casi todos los lenguajes de programación son:
• Instrucciones de entrada/salida. Instrucciones de transferencia de información entre dispositivos periféricos y
la memoria central, tales como "leer de..." o bien "escribir en...".
• Instrucciones de cálculo. Instrucciones para que la computadora pueda realizar operaciones aritméticas.
• Instrucciones de control. Instrucciones que modifican la secuencia de la ejecución del programa.
Además de estas instrucciones y dependiendo del procesador y del lenguaje de programación existirán otras que conformarán el conjunto de instrucciones y junto con las reglas de sintaxis permitirán escribir los programas de las
computadoras. Los principales tipos de lenguajes de programación son:
• Lenguajes máquina.
• Lenguajes de bajo nivel (ensambladores).
• Lenguajes de alto nivel.

2.2.-METODOLÓGICA DE LA PROGRAMACIÓN.
Poner en funcionamiento un programa informático con un objetivo específico es algo que vemos todos los días. Nuestra cotidianidad está rodeada de ejemplos de objetos que funcionan a base de programas de estas características y con los que alcanzamos un alto grado de interacción. ¿Podrías nombrar alguno?
Sin embargo, pese a lo normal que pueda parecernos, la programación es un proceso más complejo de lo esperado. Para empezar, porque es indispensable tener en cuenta elementos simultáneos que intervienen en su diseño y funcionamiento, y que para el caso incluiremos en el concepto de metodología de la programación. Se trata de todas las técnicas y conocimientos necesarios para el funcionamiento de un programa informático. Lo central del asunto es que dicho programa se estructure de tal forma que sirva para una solución concreta.
Pasos para la programación de una metodología
La programación, resumiendo, determina el proceso para la creación de una solución de carácter informático, cualquiera que sea su objetivo o naturaleza. Cada problema es distinto, del mismo modo que los pasos para implementar la solución. Pero al margen de esto, los programas informáticos diseñados para tal fin no pueden obviar una serie de elementos básicos. Veamos en qué consisten:
Diálogo o intercambio: el programa empieza por identificar el problema. Luego se centra en la comprensión del mismo. Cuanta mayor información se obtenga en esta primera fase, más acertada será la programación de la solución.
Especificación: en esta segunda etapa se establecen de manera precisa las condiciones que debe cumplir el programa para alcanzar su objetivo, que es la solución del problema identificado. Todo lo relativo a la solución debe quedar descrito y clarificado en este punto.
Diseño: el siguiente paso consiste en la construcción de un algoritmo que siga las especificidades descritas en el punto anterior.
Codificación: esta fase es una de las más importantes de todo el proceso. El algoritmo que se ha diseñado anteriormente es traducido al lenguaje propio de la programación. O dicho de otra forma, el programa cobra entidad.
Verificación: en última instancia, los responsables del proyecto realizan una serie de pruebas para confirmar la viabilidad y la utilidad de la solución. Si cumple con lo establecido en la fase de diseño, se implementa en procesos que lo requieran. Si no es así, se deben tomar medidas para corregir los fallos que impidan su normal desarrollo.
Mantenimiento: la solución implementada, que ya ha adquirido la categoría de programa informático, precisa mantenimiento cada cierto tiempo. También de esto depende su grado de eficiencia.
La documentación en un proceso de programación
Otro elemento transversal en el proceso de diseño de una solución informática es el de la documentación. Se requiere que sus responsables reúnan todos los datos de interés para la implementación del programa y que se haga un registro en cada una de las fases del proceso, atendiendo, claro está, a necesidades como:
Comentarios relacionados con el proceso de diseño y codificación.
Especificación de datos.
Diagramas de flujo o pseudocódigo.
Especificación de requisitos.
Listado de programas fuente.
Explicación de los algoritmos.
2.2.1.-ESTRUCTURA.
Las partes principales de un programa están relacionadas con dos bloques: declaraciones e instrucciones.
En las instrucciones podemos diferenciar tres partes fundamentales
Entrada de Datos:
La constituyen todas las instrucciones que toman los datos de entrada desde un dispositivo externo y los almacena en la memoria principal para que puedan ser procesados.
Proceso o algoritmo:
Está formado por las instrucciones que modifican los objetos a partir de su estado inicial (datos de entrada) hasta el estado final (resultados) dejando los objetos que lo contiene disponibles en la memoria principal.
Salida de resultados:
Conjunto de instrucciones que toman los datos finales (resultado) de la memoria principal y los envían a los dispositivos externos.
El teorema de Böhm y Jacopini (1966) dice que un programa propio puede ser escrito utilizando sólo tres tipos de estructuras de control:
*- Estructura secuencial
Una estructura de programa es secuencial si las instrucciones se ejecutan una tras otra, a modo de secuencia lineal, es decir que una instrucción no se ejecuta hasta que finaliza la anterior, ni se bifurca el flujo del programa.zz
*- Estructura selectiva o de selección
La estructura selectiva permite que la ejecución del programa se bifurque a una instrucción (o conjunto) u otra/s, según un criterio o condición lógica establecida, sólo uno de los caminos en la bifurcación será el tomado para ejecutarse.
Estructura de control selectiva simple
Estructura de control selectiva doble
Estructura de control selectiva multiple
*- Estructura de control cíclica o repetitiva
Estructura de control desde
Estructura de control mientras
2.2.2.-ORIENTADO A OBJETO.
El paradigma orientado a objetos se asocia con el proceso de programación llamado programación orientada a objetos (POO)25 consistente en un enfoque totalmente distinto al proceso procedimental. El enfoque orientado a objetos guarda analogía con la vida real. El desarrollo de software OO se basa en el diseño y construcción de objetos que se componen a su vez de datos y operaciones que manipulan esos datos. El programador define en primer lugar los objetos del problema y a continuación los datos y operaciones que actuarán sobre esos datos. Las ventajas de la programación orientada a objetos se derivan esencialmente de la estructura modular existente en la vida real y el modo de respuesta de estos módulos u objetos a mensajes o eventos que se producen en cualquier instante.
Los orígenes de la POO se remontan a los Tipos Abstractos de Datos como parte constitutiva de una estructura de datos. En este libro se dedicará un capítulo completo al estudio del TAD como origen del concepto de programación denominado objeto.
C++ lenguaje orientado a objetos, por excelencia, es una extensión del lenguaje C y contiene las tres propiedades más importantes: encapsulamiento, herencia y polimorfismo. Smalltalk es otro lenguaje orientado a objetos muy potente y de gran impacto en el desarrollo del software orientado a objetos que se ha realizado en las últimas décadas.
Hoy día Java y C# son herederos directos de C++ y C, y constituyen los lenguajes orientados a objetos más utilizados en la industria del software del siglo XXI. Visual Basic y VB.Net son otros lenguajes orientados objetos, no tan potentes como los anteriores, pero extremadamente sencillos y fáciles de aprender.
3.-PROGRAMACIÓN UTILIZANDO UN LENGUAJE DE ALTO NIVEL.
¿Qué es un lenguaje de alto nivel? Un lenguaje de alto nivel permite al programador escribir las instrucciones de un programa utilizando palabras o expresiones sintácticas. Por ejemplo, en C se pueden usar palabras tales como: case, if, for, while, etc. para construir con ellas instrucciones como:
if( numero > 0 ) printf( "El número es positivo" )
que traducido al castellano viene a decir que: si numero es mayor que cero, entonces, escribir por pantalla el mensaje: "El número es positivo".
Ésta es la razón por la que a estos lenguajes se les considera de alto nivel, porque se pueden utilizar palabras de muy fácil comprensión para el programador. En contraposición, los lenguajes de bajo nivel son aquellos que están más cerca del "entendimiento" de la máquina. Otros lenguajes de alto nivel son: Ada, BASIC, COBOL, FORTRAN, Pascal, etc.
Otra carácterística importante de los lenguajes de alto nivel es que, para la mayoría de las instrucciones de estos lenguajes, se necesitarían varias instrucciones en un lenguaje ensamblador para indicar lo mismo. De igual forma que, la mayoría de las instrucciones de un lenguaje ensamblador, también agrupa a varias instrucciones de un lenguaje máquina.
Lenguaje de alto nivel se refiere al nivel más alto de abstracción de lenguaje de máquina. En lugar de tratar con registros, direcciones de memoria y las pilas de llamadas, lenguajes de alto nivel se refieren a las variables, matrices, objetos, aritmética compleja o expresiones booleanas, subrutinas y funciones, bucles, hilos, cierres y otros conceptos de informática abstracta, con un enfoque en la facilidad de uso sobre la eficiencia óptima del programa.
Ventajas
Genera un código más sencillo y comprensible.
Escribir un código válido para diversas máquinas o sistemas operativos.
Permite utilizar paradigmas de programación
Permite crear programas complejos en relativamente menos líneas de código.
Inconvenientes
Reducción de velocidad al ceder el trabajo de bajo nivel a la máquina.
Algunos requieren que la máquina cliente posea una determinada plataforma.
3.1.-ENTORNO DE DESARROLLO.
Entorno de Desarrollo Integrado (IDE).
Un entorno de desarrollo integrado, es un entorno de programación que ha sido empaquetado como un programa de aplicación, es decir, consiste en un editor de código, un compilador, un depurador y un constructor de interfaz gráfica (GUI).
Los IDE proveen un marco de trabajo amigable para la mayoría de los lenguajes de programación tales como C++, PHP, Python, Java, C#, Delphi, Visual Basic, etc. En algunos lenguajes, un IDE puede funcionar como un sistema en tiempo de ejecución, en donde se permite utilizar el lenguaje de programación en forma interactiva, sin necesidad de trabajo orientado a archivos de texto.

Algunos ejemplos de entornos integrados de desarrollo (IDE) son los siguientes:
Eclipse
NetBeans
IntelliJ IDEA
JBuilder de Borland
JDeveloper de Oracle
KDevelop
Anjunta
Clarion
MS Visual Studio
Visual C++
Los IDE ofrecen un marco de trabajo para la mayoría de los lenguajes de programación tales como C++, Python, Java, C#, Delphi, Visual Basic, etc. En algunos lenguajes, un IDE puede funcionar como un sistema en tiempo de ejecución, en donde se permite utilizar el lenguaje de programación en forma interactiva, sin necesidad de trabajo orientado a archivos de texto.
Es posible que un mismo IDE pueda funcionar con varios lenguajes de programación. Este es el caso de Eclipse, al que mediante plagios se le puede añadir soporte de lenguajes adicionales.
Un IDE debe tener las siguientes características:
Multiplataforma
Soporte para diversos lenguajes de programación
Integración con Sistemas de Control de Versiones
Reconocimiento de Sintaxis
Extensiones y Componentes para el IDE
Integración con Framework populares
Depurador
Importar y Exportar proyectos
Múltiples idiomas
Manual de Usuarios y Ayuda
Existen diferentes versiones de los IDEs pero estos son algunos del software que utilizan IDE, estos son:
a) Eclipse: Software libre. Es uno de los entornos Java más utilizados a nivel profesional. El paquete básico de Eclipse se puede expandir mediante la instalación de plugins para añadir funcionalidades a medida que se vayan necesitando.
b) NetBeans: Software libre. Otro de los entornos Java muy utilizados, también expandible mediante plugins. Facilita bastante el diseño gráfico asociado a aplicaciones Java.
c) BlueJ: Software libre. Es un entorno de desarrollo dirigido al aprendizaje de Java (entorno académico) y sin uso a nivel profesional. Destaca por ser sencillo e incluir algunas funcionalidades dirigidas a que las personas que estén aprendiendo tengan mayor facilidad para comprender aspectos clave de la programación orientada a objetos.
d) JBuilder: Software comercial. Se pueden obtener versiones de prueba o versiones simplificadas gratuitas en la web, buscando en la sección de productos y desarrollo de aplicaciones. Permite desarrollos gráficos.
e) JCreator: Software comercial. Se pueden obtener versiones de prueba o versiones simplificadas gratuitas en la web. Este IDE está escrito en C++ y omite herramientas para desarrollos gráficos, lo cual lo hace más rápido y eficiente que otros IDEs.
3.2.-VARIABLES.
En programación, una variable está formada por un
espacio en el sistema de almacenaje (memoria principal de un ordenador) y
un nombre (un identificador) que está asociado a ese espacio. Ese espacio
contiene resto de información conocida o desconocida, es decir un valor.
El nombre de la variable es la forma usual de referirse al valor
almacenado: esta separación entre nombre y contenido permite que el nombre sea
usado independientemente de la información exacta que representa. El
identificador, en el código fuente de la computadora puede
estar ligado a un valor durante el tiempo de ejecución y el
valor de la variable puede por lo tanto cambiar durante el curso de la
ejecución del programa. El concepto de variables en computación puede no
corresponder directamente al concepto de variables en matemática. El valor
de una variable en computación no es necesariamente parte de una ecuación o fórmula como
en matemáticas. En computación una variable puede ser utilizada en un proceso
repetitivo: puede asignársele un valor en un sitio, ser luego utilizada en
otro, más adelante reasignársele un nuevo valor para más tarde utilizarla de la
misma manera. Procedimientos de este tipo son conocidos con el nombre de iteración.
En programación de computadoras, a las variables, frecuentemente se le asignan
nombres largos para hacerlos relativamente descriptivas para su uso, mientras
que las variables en matemáticas a menudo tienen nombres escuetos, formados por
uno o dos caracteres para hacer breve en su transcripción y manipulación.
El espacio en el sistema de almacenaje puede ser referido
por diferentes identificadores. Esta situación es conocida entre los angloparlantes
como "aliasing" y podría traducirse como
"sobrenombramiento" para los hispanoparlantes. Asignarle un valor a
una variable utilizando uno de los identificadores cambiará el valor al que se
puede acceder a través de los otros identificadores.
Los compiladores deben reemplazar los nombres
simbólicos de las variables con la real ubicación de los datos. Mientras que el
nombre, tipo y ubicación de una variable permanecen fijos, los datos almacenados
en la ubicación pueden ser cambiados durante la ejecución del programa.
Las variables pueden ser de longitud:
Fija.- Cuando el tamaño de la misma no variará a lo largo de
la ejecución del programa. Todas las variables, sean del tipo que
sean tienen longitud fija, salvo algunas excepciones — como las colecciones de
otras variables (arrays) o las cadenas.
Variable.- Cuando el tamaño de la misma puede variar a lo
largo de la ejecución. Típicamente colecciones de datos.
un operador es un elemento de programa que se aplica a uno o varios operandos en una expresión o instrucción. Los operadores que toman un operando, como el operador de incremento (++) o new, se conocen como operadores unarios . Los operadores que toman dos operandos, como los operadores aritméticos (+,-,*,/) se conocen como operadores binarios . Un operador, el operador condicional (?:), toma tres operandos y es el único operador ternario de C#.
La instrucción de C# siguiente contiene un solo operador unario y un único operando. El operador de incremento, ++, modifica el valor del operando y.
C#Copiary++;
La instrucción de C# siguiente contiene dos operadores binarios, cada uno con dos operandos. El operador de asignaciones, =, tiene la variable de entero y y la expresión 2 + 3 como operandos. La propia expresión 2 + 3 está compuesta del operador de suma y dos operandos, 2y 3.
C#Copiary = 2 + 3;
Operadores, evaluación y prioridad de operadores
Un operando puede ser una expresión válida que se compone de código de una longitud indeterminada y puede incluir un número cualquiera de subexpresiones. En una expresión que contiene varios operadores, el orden de aplicación de estos viene determinado por la prioridad de operador, la asociatividady los paréntesis.
Cada operador tiene una prioridad definida. En una expresión que contiene varios operadores con distintos niveles de prioridad, la prioridad de los operadores determina el orden en que estos se evalúan. Por ejemplo, la instrucción siguiente asigna 3 a n1.
n1 = 11 - 2 * 4;
La multiplicación se ejecuta en primer lugar porque tiene prioridad sobre la resta.
En la tabla siguiente se separan los operadores en categorías en función del tipo de operación que realizan. Las categorías se muestran en orden de prioridad.
Operadores principales
ExpresiónDescripciónx.y
x?.y Acceso a miembros
Acceso a miembros condicional
f(x) Invocación de método y delegado
a[x]
a?[x] Acceso a matriz e indizador
Acceso a matriz e indizador condicional
x++ Postincremento
x-- Postdecremento
new T(...) Creación de objetos y delegados
new T(...){...} Creación de objetos con inicializador. Vea Inicializadores de objeto y de colección.
new {...} Inicializador de objeto anónimo. Vea Tipos anónimos.
new T[...] Creación de matriz. Vea Matrices.
typeof(T) Obtener el objeto System.Type para T
checked(x) Evaluar expresión en contexto comprobado
unchecked(x) Evaluar expresión en contexto no comprobado
default (T) Obtener valor predeterminado de tipo T
delegate {} Función anónima (método anónimo)
Operadores unarios
ExpresiónDescripción+x identidad
-x Negación
!x Negación lógica
~x Negación bit a bit
++x Preincremento
--x Predecremento
(T)x Convertir x explícitamente en tipo T
Operadores de multiplicación
ExpresiónDescripción* Multiplicación
/ División
% Resto
Operadores de suma
ExpresiónDescripciónx + y Suma, concatenación de cadenas, combinación de delegados
x - y Resta, eliminación de delegados
Operadores de desplazamiento
ExpresiónDescripciónx << y Desplazamiento a la izquierda
x >> y Desplazamiento a la derecha
Operadores relacionales y de tipo
ExpresiónDescripciónx < y Menor que
x > y Mayor que
x <= y Menor o igual que
x >= y Mayor o igual que
x is T Devuelve true si x es T; de lo contrario, false
x as T Devuelve x escrito como T, o NULL si x no es T
Operadores de igualdad
ExpresiónDescripciónx == y Igual
x != y No igual
Operadores lógicos, condicionales y NULL
CategoríaExpresiónDescripciónAND lógico x & y AND bit a bit entero, AND lógico booleano
XOR lógico x ^ y XOR bit a bit entero, XOR lógico booleano
OR lógico x | y OR bit a bit entero, OR lógico booleano
AND condicional x && y Evalúa y solo si x es true
OR condicional x || y Evalúa y solo si x es false
Uso combinado de NULL x ?? s Se evalúa como y si x es NULL; de lo contrario, se evalúa como x
Condicional x ? y : z Se evalúa como y si x es true y como z si x es false
Operadores de asignación y anónimos
ExpresiónDescripción= Asignación
(T x) => y Función anónima (expresión lambda)
Asociatividad
Cuando dos o más operadores con la misma prioridad están presentes en una expresión, se evalúan según su asociatividad. Los operadores asociativos a la izquierda se evalúan, por orden, de izquierda a derecha. Por ejemplo, x * y / z se evalúa como (x * y) / z. Los operadores asociativos a la derecha se evalúan, por orden, de derecha a izquierda. Por ejemplo, el operador de asignación es asociativo a la derecha. De lo contrario, el código siguiente produciría un error.
C#Copiarint a, b, c;
c = 1;
// The following two lines are equivalent.
a = b = c;
a = (b = c);
// The following line, which forces left associativity, causes an error.
//(a = b) = c;
Otro ejemplo sería el operador ternario (?:), que es asociativo a la derecha. La mayoría de los operadores binarios son asociativos a la izquierda.
Independientemente de que los operadores de una expresión sean asociativos a la izquierda o a la derecha, los operandos de cada expresión se evalúan primero, de izquierda a derecha. En los siguientes ejemplos se muestra el orden de evaluación de los operadores y los operandos.
InstrucciónOrden de evaluacióna = b a, b, =
a = b + c a, b, c, +, =
a = b + c * d a, b, c, d, *, +, =
a = b * c + d a, b, c, *, d, +, =
a = b - c + d a, b, c, -, d, +, =
a += b -= c a, b, c, -=, +=
Agregar paréntesis
Se puede cambiar el orden impuesto por la prioridad de operador y la asociatividad mediante el uso de paréntesis. Por ejemplo, 2 + 3 * 2 suele evaluarse como 8, porque los operadores de multiplicación tienen prioridad sobre los operadores de suma. Sin embargo, si se escribe la expresión como (2 + 3) * 2, la suma se evalúa antes que la multiplicación y el resultado es 10. En los siguientes ejemplos se muestra el orden de evaluación en las expresiones entre paréntesis.Como en ejemplos anteriores, los operandos se evalúan antes de aplicarse el operador.
InstrucciónOrden de evaluacióna = (b + c) * d a, b, c, +, d, *, =
a = b - (c + d) a, b, c, d, +, -, =
a = (b + c) * (d - e)
3.4.-CONSTANTES.
CONSTANTE:
Una constante tiene las mismas características que una variable excepto el hecho de que su valor asignado no puede ser cambiado durante la ejecución de program
En programación, una constante es un valor que no puede ser alterado durante la ejecución de un programa.
Una constante corresponde a una longitud fija de un ·rea reservada en la memoria principal del ordenador, donde el programa almacena valores fijos
Por conveniencia, el nombre de las constantes suele escribirse en may˙sculas en la mayoría de lenguajes


3.5.-PALABRAS RESERVADAS.
En los lenguajes informáticos una palabra reservada es una palabra que tiene un significado gramatical especial para ese lenguaje y no puede ser utilizada como un identificador de objetos en códigos del mismo, como pueden ser las variables.
Por ejemplo, en SQL, un usuario no puede ser llamado "group", porque la palabra group es usada para indicar que un identificador se refiere a un grupo, no a un usuario. Al tratarse de una palabra clave su uso queda restringido.
Ocasionalmente la especificación de un lenguaje de programación puede tener palabras reservadas que están previstas para un posible uso en futuras versiones. En Java consty goto son palabras reservadas — no tienen significado en Java, pero tampoco pueden ser usadas como identificadores. Al reservar los términos pueden ser implementados en futuras versiones de Java, si se desea, sin que el código fuente más antiguo escrito en Java deje de funcionar.
Palabras reservadas e independencia del lenguaje
En la CLI de .NET, todos los lenguajes tienen que proporcionar un mecanismo para utilizar los identificadores públicos que son palabras reservadas en ese lenguaje. .|. Para ver por qué es necesario, supongamos que se define una clase en VB.NET como sigue:
Public Class this
End Class
Entonces, se compila esta clase en un ensamblado de .NET y se distribuye como parte de un conjunto de herramientas. Un programador de C#, que quiere definir una variable de tipo “this” encontraría un problema: “this” es una palabra reservada en C#. El siguiente fragmento en C# no compilará:
this x = new this();
Un tema similar aparece cuando se accede a miembros, sobrescribiendo métodos virtuales e identificando espacios de nombres. En C#, colocando la arroba (@) antes del identificador, se forzará a ser considerado como un identificador en vez de una palabra reservada por el compilador. El signo arroba no es considerado parte del identificador.
@this x = new @this();
Por consistencia, esta utilización también se permite en configuraciones no-públicas como variables locales, nombres de parámetros y miembros privados.
3.6.-SENTENCIA DE DECISIÓN.
Las sentencias de decisión o también llamadas de CONTROL DE FLUJO son estructuras de control que realizan una pregunta la cual retorna verdadero o falso (evalúa una condicion) y selecciona la siguiente instrucción a ejecutar dependiendo la respuesta o resultado.
Las instrucciones comienzan a ejecutarse de forma secuencial (en orden) y cuando se llega a una estructura condicional, la cual esta asociada a una condicion, se decide que camino tomar dependiendo siempre del resultado de la condicion siendo esta falsa o verdadera.En algún momento dentro de nuestros algoritmos, es preciso cambiar el flujo de ejecución de las instrucciones, es decir, el orden en que las instrucciones son ejecutadas. Muchas de las veces tenemos que tomar una decisión en cuanto a que se debe ejecutar basándonos en una respuesta de verdadero o falso (condicion).
La ejecución de las instrucciones incluyendo una estructura de control como el condicional funcionan de esta manera:
Cuando se termina de ejecutar este bloque de instrucciones se reanuda la ejecución en la instrucción siguiente a la de la condicional.
La instrucción if es, por excelencia, la más utilizada para construir estructuras de control de flujo.
SINTAXIS
Primera Forma
Ahora bién, la sintaxis utilizada en la programación de C++ es la siguiente:if (condicion)
{
Set de instrucciones
}
siendo "condicion" el lugar donde se pondrá la condición que se tiene que cumplir para que sea verdadera la sentencia y así proceder a realizar el "set de instrucciones" o código contenido dentro de la sentencia.
Segunda Forma
Ahora veremos la misma sintaxis pero ahora le añadiremos la parte "Falsa" de la sentencia:if (condicion)
{
Set de instrucciones //PARTE VERDADERA
}
else
{
Set de instrucciones 2 //Parte FALSA
}
La forma mostrada anteriormente muestra la union de la parte "VERDADERA" con la nueva secuencia la cual es la parte "FALSA" de la sentencia de decision "IF" en la cual esta compuesta por el:else
{
Set de instrucciones 2 //Parte FALSA
}
la palabra "else" o "De lo contrario" indica al lenguaje que de lo contrario al no ser verdadera o no se cumpla la parte verdadera entonces realizara el "set de instrucciones 2".
EJEMPLOS DE SENTENCIAS IF...
Ejemplo 1:if(numero == 0) //La condicion indica que tiene que ser igual a Cero
{
cout<<"El Numero Ingresado es Igual a Cero";
}
Ejemplo 2:if(numero > 0) // la condicion indica que tiene que ser mayor a Cero
{
cout<<"El Numero Ingresado es Mayor a Cero";
}
Ejemplo 3:if(numero < 0) // la condicion indica que tiene que ser menor a Cero
{
cout<<"El Numero Ingresado es Menor a Cero";
}
Ahora uniremos todos estos ejemplos para formar un solo programa mediante la utilización de la sentencia "Else" e introduciremos el hecho de que se puede escribir en este espacio una sentencia if ya que podemos ingresar cualquier tipo de código dentro de la sentencia escrita después de un Else.
Ejemplo 4:if(numero == 0) //La condicion indica que tiene que ser igual a Cero
{
cout<<"El Numero Ingresado es Igual a Cero";
}
else
{
if(numero > 0) // la condicion indica que tiene que ser mayor a Cero
{
cout<<"El Numero Ingresado es Mayor a Cero";
}
else
{
if(numero < 0) // la condicion indica que tiene que ser menor a Cero
{
cout<<"El Numero Ingresado es Menor a Cero";
}
}
}
Sentencia switch
switch es otra de las instrucciones que permiten la construcción de estructuras de control. A diferencia de if, para controlar el flujo por medio de una sentencia switchse debe de combinar con el uso de las sentencias case y break.
Notas: cualquier número de casos a evaluar por switch así como la sentencia default son opcionales. La sentencia switch es muy útil en los casos de presentación de menus.
Sintaxis:switch (condición)
{
case primer_caso:
bloque de instrucciones 1
break;
case segundo_caso:
bloque de instrucciones 2
break;
case caso_n:
bloque de instrucciones n
break;
default: bloque de instrucciones por defecto
}
Ejemplo 1
switch (numero)
{
case 0: cout << "numero es cero";
}
Ejemplo 2
switch (opcion)
{
case 0: cout << "Su opcion es cero"; break;
case 1: cout << "Su opcion es uno"; break;
case 2: cout << "Su opcion es dos";
}
Ejemplo 3
switch (opcion)
{
case 1: cout << "Su opcion es 1"; break;
case 2: cout << "Su opcion es 2"; break;
case 3: cout << "Su opcion es 3"; break;
default: cout << "Elija una opcion entre 1 y 3";
}
Operador condicional ternario ?:
En C/C++, existe el operador condicional ( ?: ) el cual es conocido por su estructura como ternario. El comportamiento de dicho operador es el mismo que una estructura if - then - else del lenguaje BASIC (y de la función IIf de Visual Basic). El operador condicional ?: es útil para evaluar situaciones tales como:
Si se cumple tal condición entonces haz esto, de lo contrario haz esto otro.
Sintaxis:( (condicion) ? proceso1 : proceso2 )
En donde, condicion es la expresión que se evalua, proceso1 es la tarea a realizar en el caso de que la evaluación resulte verdadera, y proceso2 es la tarea a realizar en el caso de que la evaluación resulte falsa.
Ejemplo 1
int edad;
cout << "Cual es tu edad: ";
cin >> edad;
cout << ( (edad < 18) ? "Eres joven aun" : "Ya tienes la mayoría de edad" );
El ejemplo anterior podría escribirse de la siguiente manera:
int edad;
cout << "Cual es tu edad: ";
cin >> edad;
if (edad < 18) cout << "Eres joven aun";
else cout << "Ya tienes la mayoría de edad";
Ejemplo 2
Vamos a suponer que deseamos escribir una función que opere sobre dos valores numéricos y que la misma ha de regresar 1 (true) en caso de que el primer valor pasado sea igual al segundo valor; en caso contrario la función debe retornar 0 (false).
int es_igual( int a, int b)
{
return ( (a == b) ? 1 : 0 )
}
Sentencias de iteración
DEFINICIÓN
Las Sentencias de Iteración o Ciclos son estructuras de control que repiten la ejecución de un grupo de instrucciones. Básicamente, una sentencia de iteración es una estructura de control condicional, ya que dentro de la misma se repite la ejecución de una o más instrucciones mientras que una a condición especifica se cumpla. Muchas veces tenemos que repetir un número definido o indefinido de veces un grupo de instrucciones por lo que en estos casos utilizamos este tipo de sentencias. en C++ los ciclos o bucles se construyen por medio de las sentencias for, while y do - while. La sentencia for es útil para los casos en donde se conoce de antemano el número de veces que una o más sentencias han de repetirse. Por otro lado, la sentencia while es útil en aquellos casos en donde no se conoce de antemano el número de veces que una o más sentencias se tienen que repetir.
Sentencias For
for(contador; final; incremento)
{
Codigo a Repetir;
}
donde:
contador es una variable numérica
final es la condición que se evalua para finalizar el ciclo (puede ser independiente del contador)
incremento es el valor que se suma o resta al contador
Hay que tener en cuenta que el "for" evalua la condición de finalización igual que el while, es decir, mientras esta se cumpla continuaran las repeticiones.
Ejemplo 1:
for(int i=1; i<=10; i++)
{
cout<<"Hola Mundo";
}
Esto indica que el contador "i" inicia desde 1 y continuará iterando mientras i sea menor o igual a 10 ( en este caso llegará hasta 10) e "i++" realiza la sumatoria por unidad lo que hace que el for y el contador se sumen. repitiendo 10 veces "HOLA MUNDO" en pantalla.
Ejemplo 2:
for(int i=10; i>=0; i--)
{
cout<<"Hola Mundo";
}
Este ejemplo hace lo mismo que el primero, salvo que el contador se inicializa a 10 en lugar de 1; y por ello cambia la condición que se evalua así como que el contador se decrementa en lugar de ser incrementado.
La condición también puede ser independiente del contador:
Ejemplo 3:
int j = 20;
for(int i=0; j>0; i++){
cout<<"Hola"<<i<<" - "<<j<<endl;
j--;
}
En este ejemplo las iteraciones continuaran mientras j sea mayor que 0, sin tener en cuenta el valor que pueda tener i.
Sentencia while
while(condicion)
{
código a Repetir
}
donde:
condicion es la expresión a evaluar
Ejemplo 1:
int contador = 0;
while(contador<=10)
{
contador=contador+1;
cout<<"Hola Mundo";
}
El contador Indica que hasta que este llegue a el total de 10 entonces se detendrá y ya no se realizará el código contenido dentro de la sentencia while, de lo contrario mientras el "contador" sea menor o igual a 10 entonces el código contenido se ejecutará desplegando hasta 11 veces "Hola Mundo" en pantalla.
Sentencia do - while
La sentencia do es usada generalmente en cooperación con while para garantizar que una o más instrucciones se ejecuten al menos una vez. Por ejemplo, en la siguiente construcción no se ejecuta nada dentro del ciclo while, el hecho es que el contador inicialmente vale cero y la condición para que se ejecute lo que está dentro del while es "mientras el contador sea mayor que diez". Es evidente que a la primera evaluación hecha por while la condición deja de cumplirse.
int contador = 0;
while(contador > 10)
{
contador ++;
cout<<"Hola Mundo";
}
Al modificar el segmento de código anterior usando do tenemos:
int contador = 0;
do
{
contador ++;
cout<<"Hola Mundo";
}
while(contador > 10);
Observe cómo en el caso de do la condición es evaluada al final en lugar de al principio del bloque de instrucciones y, por lo tanto, el código que le sigue al do se ejecuta al menos la primera vez.
(Sentencia switch) vimos que la sentencia break es utilizada con el propósito de forzar un salto dentro del bloque switch hacia el final del mismo. En esta sección volveremos a ver el uso de break, salvo que esta ocasión la usaremos junto con las sentecias for y la sentencia while. Además, veremos el uso de la sentencia continue.
break
La sentencia break se usa para forzar un salto hacia el final de un ciclo controlado por for o por while.
Ejemplo:
En el siguiente fragmento de código la sentencia break cierra el ciclo for cuando la variable ( i ) es igual a 5. La salida para el mismo será:0 1 2 3 4
for (int i=0; i<10; i++) {
if (i == 5) break;
cout << i << " ";
}
continue
La sentencia continue se usa para ignorar una iteración dentro de un ciclo controlado por for o por while.
Ejemplo:
En el siguiente fragmento de código la sentencia continue ignora la iteración cuando la variable ( i ) es igual a 5. La salida para el mismo será:0 1 2 3 4 6 7 8 9
for (int i=0; i<10; i++) {
if (i == 5) continue;
cout << i << " ";
}
Uso de break y continue junto con while
Los dos ejemplos anteriores se presentan en seguida, salvo que en lugar de for se hace uso de while.
Nota: no deje de observar que la construcción del ciclo while para el caso de la sentencia continue es diferente, esto para garantizar que el ciclo no vaya a caer en una iteración infinita.
break
int i = 0;
while (i<10) {
if (i == 5) break;
cout << i << " ";
i++;
}
continue
int i = -1;
while (i<10) {
i++;
if (i == 5) continue;
cout << i << " ";
}
3.7.- ESTRUCTURA.
Una estructura es un tipo de dato compuesto que permite almacenar un conjunto de datos de diferente tipo. Los datos que contiene una estructura pueden ser de tipo simple (caracteres, números enteros o de coma flotante etc.) o a su vez de tipo compuesto (vectores, estructuras, listas, etc.).
A cada uno de los datos o elementos almacenados dentro de una estructura se les denomina miembros
de esa estructura y éstos pertenecerán a un tipo de dato determinado.
La definición de una estructura en C corresponde con la sintaxis siguiente:
En esta declaración aclararemos que:
struct: es una palabra reservada de C que indica que los elementos que vienen agrupados a continuación entre llaves componen una estructura.
nombre_estructura: identifica el tipo de dato que se describe y del cual se podrán declarar variables. Se especifica entre corchetes para indicar su opcionalidad.
miembro1, miembro2,...: Son los elementos que componen la estructura de datos, deben ser precedidos por el tipo_dato al cual pertenecen.
Recordemos que una estructura define un tipo de dato, no una variable, lo que significa que no existe reserva de memoria cuando el compilador está analizando la estructura. Posteriormente habrá que declarar variables del tipo definido por la estructura para poder almacenar y manipular datos.
La declaración de variables de un determinado tipo de estructura de datos se puede realizar de dos modos:
Primera: Incluir en la propia definición de la estructura aquellas variables que se van a emplear en el programa. Esta declaración de variables implica que el ámbito en el que éstas son reconocidas será el mismo que el de la declaración del tipo de dato estructura. La sintaxis es:
En estos casos, y si no se van a declarar más variables de este tipo de dato en otros lugares del programa, el nombre_estructura es innecesario, por ello viene entre corchetes.
Ejemplo: estructura de una tarjeta bancaria, utilizando esta primera forma:
struct {
long_int num_tarjeta;
char tipo_cuenta;
char nombre [80];
float saldo;
} cliente1, cliente2;
Segunda: Definir el tipo de dato estructura con un nombre determinado y declarar posteriormente las variables de ese tipo de dato. Para ello la estructura se identificará con un nombre de forma obligatoria.
Ejemplo: estructura de una tarjeta bancaria, utilizando la segunda forma:
struct {
long_int num_tarjeta;
char tipo_cuenta;
char nombre [80];
float saldo;
}
struct tarjetas cli1, cli2;
3.7.1.-CONDICIÓN.
En programación, una condición es toda sentencia de la cual se puede determinar su verdad (TRUE) o falsedad (FALSE). En su gran mayoría, son comparaciones. Por ejemplo,
4 > 5; // ésta sentencia es una condición porque tiene resultado verdadero o falso; en este caso falso porque 4 no es mayor a 5.
echo “BlogdePHP” // ésta sentencia no es condición puesto que no hay para comparar, no se puede determinar verdad o falsedad.
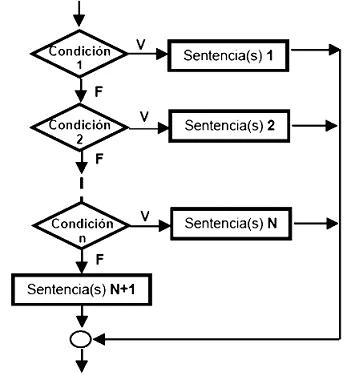
Las condiciones tienen una utilidad muy importante en los bucles (también llamados ciclos). Por lo general, en la iteración que la condición toma un valor falso (FALSE) se produce el corte del bucle. Cuando se utilizan así, se denominan condición de corte.
En programación, una sentencia condicional es una instrucción o grupo de instrucciones que se pueden ejecutar o no en función del valor de una condición.
Los tipos más conocidos de sentencias condicionales son el SI..ENTONCES (if..then), el SI..ENTONCES..SI NO (if..then..else) y el SEGÚN (case o switch), aunque también podríamos mencionar al manejo de excepciones como una alternativa más moderna para evitar el "anidamiento" de sentencias condicionales.
Las sentencias condicionales constituyen, junto con los bucles, los pilares de la programación estructurada, y su uso es una evolución de una sentencia en lenguaje ensamblador que ejecutaba la siguiente línea o no en función del valor de una condición.
3.7.2.-REPETICIÓN.
Esta estructura ejecuta las acciones del cuerpo del bucle un numero especifico de veces, y de modo automatico controla el numero de iteraciones o pasos.
ESTRUCTURA FOR
for( <expr1> ; <expr2> ; <expr3> )
<bloque de instrucciones>
<expr1> es evaluada una vez antes de entrar al ciclo. Es utilizada para inicializar los datos del ciclo.
<expr2> es evaluada antes de cada ciclo. Es utilizada para decidir si el ciclo continúa o termina.
<expr3> es evaluada al final de cada ciclo. Es utilizada para asignar el nuevo valor a los datos del ciclo.
MIENTRAS (WHILE) 
La estructura mientras que (while) es aquella en la que el número de repeticiones de bucle no se conoce por anticipado, y el cuerpo del buque se repite mientras se cumple una determinada condición.
Una condición es una expresión booleana (puede ver verdadera o falsa) que se evalua al principio del bucle y antes de cada iteración de las sentencias.
· Si la condición es verdadera, se ejecuta el bloque de sentencias y se vuelve al principio del bucle.
· Si la condición es falsa, no se ejecuta el bloque de sentencias y se continúa con la siguiente sentencia del programa.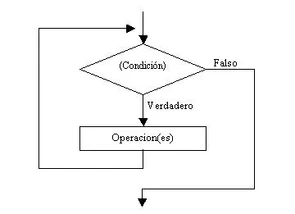
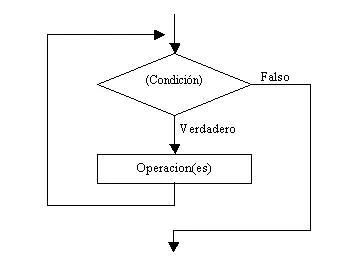
DO WHILE
La estructura do - while es similar a la estructura while, con la siguiente diferencia:
while evalúa la condición antes de ejecutar el bloque de instrucciones.
do - while evalúa la condición después de haber ejecutado el bloque de instrucciones. Así, el bloque de instrucciones es ejecutado por lo menos una vez.
do
<bloque de instrucciones>
while ( <expresión> );
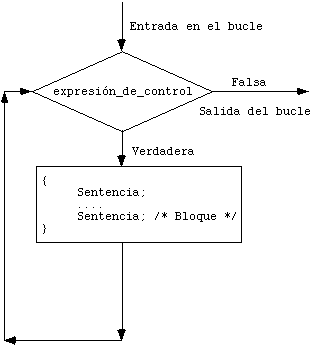
El bloque <bloque de instrucciones> es ejecutado al menos una vez y también es ejecutado mientras que la <expresión> sea igual a un valor diferente de cero.
En la práctica, la estructura do - while no es más frecuentemente usada que el ciclo while, sin embargo, en ciertos casos su uso constituye una solución más elegante. Una aplicación típica del ciclo do - while es la captura de datos que deben cumplir con cierta condición:
4.-ARREGLOS.
Las estructuras de datos que hemos visto hasta ahora (listas, tuplas, diccionarios, conjuntos) permiten manipular datos de manera muy flexible. Combinándolas y anidándolas, es posible organizar información de manera estructurada para representar sistemas del mundo real.
En muchas aplicaciones de Ingeniería, por otra parte, más importante que la organización de los datos es la capacidad de hacer muchas operaciones a la vez sobre grandes conjuntos de datos numéricos de manera eficiente. Algunos ejemplos de problemas que requieren manipular grandes secuencias de números son: la predicción del clima, la construcción de edificios, y el análisis de indicadores financieros entre muchos otros.
La estructura de datos que sirve para almacenar estas grandes secuencias de números (generalmente de tipo float) es el arreglo.
Los arreglos tienen algunas similitudes con las listas:
los elementos tienen un orden y se pueden acceder mediante su posición,
los elementos se pueden recorrer usando un ciclo for.
Sin embargo, también tienen algunas restricciones:
todos los elementos del arreglo deben tener el mismo tipo,
en general, el tamaño del arreglo es fijo (no van creciendo dinámicamente como las listas),
se ocupan principalmente para almacenar datos numéricos.
A la vez, los arreglos tienen muchas ventajas por sobre las listas, que iremos descubriendo a medida que avancemos en la materia.
Los arreglos son los equivalentes en programación de las matrices y vectores de las matemáticas. Precisamente, una gran motivación para usar arreglos es que hay mucha teoría detrás de ellos que puede ser usada en el diseño de algoritmos para resolver problemas verdaderamente interesantes.
Crear arreglos
El módulo que provee las estructuras de datos y las funciones para trabajar con arreglos se llama NumPy, y no viene incluído con Python, por lo que hay que instalarlo por separado.
Descargue el instalador apropiado para su versión de Python desde la página de descargas de NumPy. Para ver qué versión de Python tiene instalada, vea la primera línea que aparece al abrir una consola.
Para usar las funciones provistas por NumPy, debemos importarlas al principio del programa:
from numpy import array
Como estaremos usando frecuentemente muchas funciones de este módulo, conviene importarlas todas de una vez usando la siguiente sentencia:
from numpy import *
(Si no recuerda cómo usar el import, puede repasar la materia sobre módulos).
El tipo de datos de los arreglos se llama array. Para crear un arreglo nuevo, se puede usar la función array pasándole como parámetro la lista de valores que deseamos agregar al arreglo:
>>> a = array([6, 1, 3, 9, 8])
>>> a
array([6, 1, 3, 9, 8])
Todos los elementos del arreglo tienen exactamente el mismo tipo. Para crear un arreglo de números reales, basta con que uno de los valores lo sea:
>>> b = array([6.0, 1, 3, 9, 8])
>>> b
array([ 6., 1., 3., 9., 8.])
Otra opción es convertir el arreglo a otro tipo usando el método astype:
>>> a
array([6, 1, 3, 9, 8])
>>> a.astype(float)
array([ 6., 1., 3., 9., 8.])
>>> a.astype(complex)
array([ 6.+0.j, 1.+0.j, 3.+0.j, 9.+0.j, 8.+0.j])
Hay muchas formas de arreglos que aparecen a menudo en la práctica, por lo que existen funciones especiales para crearlos:
zeros(n) crea un arreglo de n ceros;
ones(n) crea un arreglo de n unos;
arange(a, b, c) crea un arreglo de forma similar a la función range, con las diferencias que a, b y c pueden ser reales, y que el resultado es un arreglo y no una lista;
linspace(a, b, n) crea un arreglo de n valores equiespaciados entre a y b.
>>> zeros(6)
array([ 0., 0., 0., 0., 0., 0.])
>>> ones(5)
array([ 1., 1., 1., 1., 1.])
>>> arange(3.0, 9.0)
array([ 3., 4., 5., 6., 7., 8.])
>>> linspace(1, 2, 5)
array([ 1. , 1.25, 1.5 , 1.75, 2. ])
Operaciones con arreglos
Las limitaciones que tienen los arreglos respecto de las listas son compensadas por la cantidad de operaciones convenientes que permiten realizar sobre ellos.
Las operaciones aritméticas entre arreglos se aplican elemento a elemento:
>>> a = array([55, 21, 19, 11, 9])
>>> b = array([12, -9, 0, 22, -9])
# sumar los dos arreglos elemento a elemento
>>> a + b
array([67, 12, 19, 33, 0])
# multiplicar elemento a elemento
>>> a * b
array([ 660, -189, 0, 242, -81])
# restar elemento a elemento
>>> a - b
array([ 43, 30, 19, -11, 18])
Las operaciones entre un arreglo y un valor simple funcionan aplicando la operación a todos los elementos del arreglo, usando el valor simple como operando todas las veces:
>>> a
array([55, 21, 19, 11, 9])
# multiplicar por 0.1 todos los elementos
>>> 0.1 * a
array([ 5.5, 2.1, 1.9, 1.1, 0.9])
# restar 9.0 a todos los elementos
>>> a - 9.0
array([ 46., 12., 10., 2., 0.])
Note que si quisiéramos hacer estas operaciones usando listas, necesitaríamos usar un ciclo para hacer las operaciones elemento a elemento.
Las operaciones relacionales también se aplican elemento a elemento, y retornan un arreglo de valores booleanos:
>>> a = array([5.1, 2.4, 3.8, 3.9])
>>> b = array([4.2, 8.7, 3.9, 0.3])
>>> c = array([5, 2, 4, 4]) + array([1, 4, -2, -1]) / 10.0
>>> a < b
array([False, True, True, False], dtype=bool)
>>> a == c
array([ True, True, True, True], dtype=bool)
Para reducir el arreglo de booleanos a un único valor, se puede usar las funciones any y all. anyretorna True si al menos uno de los elementos es verdadero, mientras que all retorna True sólo si todos lo son (en inglés, any signfica «alguno», y all significa «todos»):
>>> any(a < b)
True
>>> any(a == b)
False
>>> all(a == c)
True
Funciones sobre arreglos
NumPy provee muchas funciones matemáticas que también operan elemento a elemento. Por ejemplo, podemos obtener el seno de 9 valores equiespaciados entre 0 y π/2 con una sola llamada a la función sin:
>>> from numpy import linspace, pi, sin
>>> x = linspace(0, pi/2, 9)
>>> x
array([ 0. , 0.19634954, 0.39269908,
0.58904862, 0.78539816, 0.9817477 ,
1.17809725, 1.37444679, 1.57079633])
>>> sin(x)
array([ 0. , 0.19509032, 0.38268343,
0.55557023, 0.70710678, 0.83146961,
0.92387953, 0.98078528, 1. ])
Como puede ver, los valores obtenidos crecen desde 0 hasta 1, que es justamente como se comporta la función seno en el intervalo [0, π/2].
Aquí también se hace evidente otra de las ventajas de los arreglos: al mostrarlos en la consola o al imprimirlos, los valores aparecen perfectamente alineados. Con las listas, esto no ocurre:
>>> list(sin(x))
[0.0, 0.19509032201612825, 0.38268343236508978, 0.5555702330
1960218, 0.70710678118654746, 0.83146961230254524, 0.9238795
3251128674, 0.98078528040323043, 1.0]
Arreglos aleatorios
El módulo NumPy contiene a su vez otros módulos que proveen funcionalidad adicional a los arreglos y funciones básicos.
El módulo numpy.random provee funciones para crear números aleatorios (es decir, generados al azar), de las cuales la más usada es la función random, que entrega un arreglo de números al azar distribuidos uniformemente entre 0 y 1:
>>> from numpy.random import random
>>> random(3)
array([ 0.53077263, 0.22039319, 0.81268786])
>>> random(3)
array([ 0.07405763, 0.04083838, 0.72962968])
>>> random(3)
array([ 0.51886706, 0.46220545, 0.95818726])
Obtener elementos de un arreglo
Cada elemento del arreglo tiene un índice, al igual que en las listas. El primer elemento tiene índice 0. Los elementos también pueden numerarse desde el final hasta el principio usando índices negativos. El último elemento tiene índice —1:
>>> a = array([6.2, -2.3, 3.4, 4.7, 9.8])
>>> a[0]
6.2
>>> a[1]
-2.3
>>> a[-2]
4.7
>>> a[3]
4.7
Una seccion del arreglo puede ser obtenida usando el operador de rebanado a[i:j]. Los índices i y jindican el rango de valores que serán entregados:
>>> a
array([ 6.2, -2.3, 3.4, 4.7, 9.8])
>>> a[1:4]
array([-2.3, 3.4, 4.7])
>>> a[2:-2]
array([ 3.4])
Si el primer índice es omitido, el rebanado comienza desde el principio del arreglo. Si el segundo índice es omitido, el rebanado termina al final del arreglo:
>>> a[:2]
array([ 6.2, -2.3])
>>> a[2:]
array([ 3.4, 4.7, 9.8])
Un tercer índice puede indicar cada cuántos elementos serán incluídos en el resultado:
>>> a = linspace(0, 1, 9)
>>> a
array([ 0. , 0.125, 0.25 , 0.375, 0.5 , 0.625, 0.75 , 0.875, 1. ])
>>> a[1:7:2]
array([ 0.125, 0.375, 0.625])
>>> a[::3]
array([ 0. , 0.375, 0.75 ])
>>> a[-2::-2]
array([ 0.875, 0.625, 0.375, 0.125])
>>> a[::-1]
array([ 1. , 0.875, 0.75 , 0.625, 0.5 , 0.375, 0.25 , 0.125, 0. ])
Una manera simple de recordar cómo funciona el rebanado es considerar que los índices no se refieren a los elementos, sino a los espacios entre los elementos
Algunos métodos convenientes
Los arreglos proveen algunos métodos útiles que conviene conocer.
Los métodos min y max, entregan respectivamente el mínimo y el máximo de los elementos del arreglo:
>>> a = array([4.1, 2.7, 8.4, pi, -2.5, 3, 5.2])
>>> a.min()
-2.5
>>> a.max()
8.4000000000000004
Los métodos argmin y argmax entregan respectivamente la posición del mínimo y del máximo:
>>> a.argmin()
4
>>> a.argmax()
2
Los métodos sum y prod entregan respectivamente la suma y el producto de los elementos:
>>> a.sum()
24.041592653589795
>>> a.prod()
-11393.086289208301
papi arca
ResponderEliminarMuy bien Juan, Tienes un punto extra
ResponderEliminar